Scalability of a digital product is often understood as the ability to withstand growth in users and traffic. However, in practice scalability is a business property: it determines the speed of feature delivery to market, the stability of user experience, operational costs, and the level of reputational risk. In mobile products this is compounded by platform-specific factors: heterogeneity of devices, limited resources, unstable networks, and the inertia of releases through application stores.
This article examines which architectural decisions in mobile applications and backend services most significantly affect business metrics (conversion, retention, support request frequency, total cost of ownership of infrastructure) and how to build an engineering decision-making framework: from observability and SLOs to controlled releases and resilience to peak loads. A practical scheme “observe → decide → implement → measure” is proposed, enabling the linkage of system indicators (latency, errors, crash rate) with product outcomes and allowing growth to be managed without degradation of quality.
Introduction
Growth of a digital product rarely looks like a “smooth increase in load.” It usually comes in jumps: marketing campaigns, expansion into new regions, seasonality, new integrations, changes in regulatory requirements, emergence of new usage scenarios. Mobile applications amplify this variability: users operate on devices with different performance characteristics and memory capacities, in networks with high latency and packet loss, under constraints of background activity and energy consumption. At the same time, the process of delivering changes to the mobile environment itself involves delays: releases go through application stores, and updates on the user side are spread over time.
In such an environment, architecture ceases to be a “system blueprint” and becomes a mechanism for managing risk and business velocity. When architectural decisions are successful, teams release changes frequently and safely, the product remains responsive, and incidents are localized and resolved quickly. When they are not, growth turns into a chain of crises: conversion drops due to delays, ratings decline because of crashes, the load on support increases, infrastructure costs grow, and constant “firefighting” consumes engineering time.
The purpose of this article is to systematically show how engineering decisions translate into business outcomes, and which practices make scalability manageable, measurable, and reproducible.

Main Sections (Semantic Blocks)
1. Scalability as “Product Economics,” Not “More Servers”
In engineering reality, scalability is often reduced to server performance and the ability of a database to withstand load. However, the business does not deal with CPUs, but with consequences:
- increased response time in key scenarios (login, payments, search, checkout) leads to a drop in conversion;
- instability and crashes reduce trust and worsen retention;
- complexity of releases limits the speed of feature delivery, and therefore the speed of experiments and revenue growth;
- frequent incidents increase operational costs and burn out the team;
- infrastructure expenses grow faster than value if the system scales “inefficiently.”
From this follows a principle: an architectural decision is justified if it improves one of the “economic” characteristics of the product — speed of change, predictability of quality, cost of operation, or level of risk.

2. Mobile Scalability: Growth of Users + Growth of the Codebase
A mobile application scales along two dimensions: (i) the audience and diversity of devices grow, and (ii) functionality and the codebase grow. Without architectural discipline, this leads to an increase in application size, longer startup times, higher memory consumption, fragmentation of logic, and increased testing complexity.
Practically significant architectural decisions on the mobile side usually include:
- modularity (separation by domains/features and by layers) to localize changes and speed up builds and tests;
- contractual interactions (clear interfaces between modules) so that changes do not cause cascading effects;
- dependency management (reducing “heavy” libraries and cyclic dependencies), which directly affects stability and development speed;
- a realistic release strategy (client–server version compatibility), because “all users will update today” is a false assumption.
From a business perspective, this translates into measurable effects: fewer regression defects, higher feature delivery speed, lower maintenance costs, and a more stable user experience.
3. Backend Scaling: Resilience, Data, and Managed Degradation
On the backend side, scalability is determined not only by “capacity,” but by the structure of the system: how responsibilities are distributed, how data is organized, how autonomous services are, and how the system behaves under abnormal conditions.
The most common engineering principles that directly improve business resilience include:
- horizontal scalability of services (prioritizing a stateless approach wherever possible);
- caching as a tool for stabilizing latency and protecting against spikes, with controlled invalidation and consistency;
- clear data and responsibility boundaries (reducing tight coupling between services), which accelerates development;
- managed degradation: under overload, the system should “shed” secondary functionality while preserving critical flows (for example, payments and authentication);
- robust timeout and retry policies: uncontrolled retries often amplify incidents and turn partial failures into cascading ones.
For the business, the key is not the complete absence of errors as such, but the system’s ability to remain predictable during growth and under stress scenarios.
4. Observability as a Bridge Between Engineering and Product
Even a strong architecture degrades if the team does not see the real picture. Observability makes scalability manageable because it allows teams to answer the questions: “what is happening?”, “why is it happening?”, “what has changed?”, and “what is the effect of a release?”.
A practical observability toolkit for a mobile + backend product typically includes:
- SLOs (target levels of availability, latency, and errors) defined in terms of user experience rather than only internal metrics;
- tracing to understand latency chains and points of failure;
- client-side metrics (RUM/telemetry) — real signals from devices: startup time, frame stability, crash frequency, network errors;
- correlation between releases and degradations (to quickly identify which deployment worsened a metric and decide on rollback or fix).
Observability is what turns architecture from a set of “intentions” into a measurable system for managing quality and risk.
5. Engineering “Levers” with the Strongest Impact on Business Metrics
In practice, several technical factors repeatedly produce the most visible business impact:
- latency and its “tails” (p95/p99) in key user flows. It is not average latency that defines experience, but worst-case scenarios that users remember and that break conversion;
- crash-free rate and stability. For a mobile product, this is a direct factor of trust and app store ratings, influencing organic growth;
- release frequency and safety. Fast but controlled releases increase the speed of experimentation and reduce the cost of fixes;
- infrastructure cost. If user growth is accompanied by disproportionate cost growth, scaling becomes economically toxic;
- reduction of security risks. In large products, security is not an “add-on” but a trust component that affects partnerships, regulation, and reputation.
Importantly, these points are not abstract engineering goals, but measurable business parameters that can be directly linked to conversion, retention, and operational expenses.
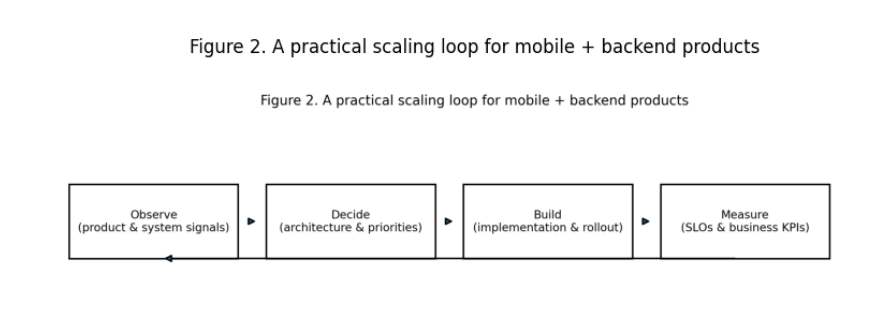
6. The “Observe → Decide → Implement → Measure” Loop as a Model for Engineering Growth Management
From a practical standpoint, scaling is most effectively implemented as a continuous cycle:
- Observe: product and system signals (latency, errors, crashes, load, cost, user behavior);
- Decide: architectural priorities and constraints (what to optimize, where the bottleneck is, which risks are acceptable);
- Implement: changes in small steps (phased releases, feature flags, canary deployments);
- Measure: impact on SLOs and business KPIs (conversion, retention, support ticket frequency, NPS/ratings).
This model is especially important for experienced engineers working in international product environments: it helps avoid “architecture for architecture’s sake” and justify decisions through their effect on the product.
Conclusion
Scalable architecture of mobile and backend systems is not only a technical ability to withstand growth, but also a business tool: it accelerates feature delivery, reduces the frequency and severity of incidents, stabilizes user experience, and keeps infrastructure costs within manageable limits. The most sustainable results are achieved when architectural decisions are made not “by intuition,” but through observability, SLOs, and a clear connection to product economics. The “observe → decide → implement → measure” loop allows teams to grow without degradation of quality, turning scaling into a predictable investment rather than an emergency response to the next traffic spike.
References
- Beyer B., Jones C., Petoff J., Murphy N. Site Reliability Engineering. O’Reilly.
- Kleppmann M. Designing Data-Intensive Applications. O’Reilly.
- Nygard M. Release It!. Pragmatic Bookshelf.
- Fowler M. Patterns of Enterprise Application Architecture. Addison-Wesley.
- Google. Site Reliability Workbook